语音转文字
只有whisper.cpp文件和whisper.h文件是项目的核心文件,其他代码都是ggml的机器学习框架代码。
examples中的代码是命令行中调用./main ***时实际调用whisper.cpp文件进行语音转文字的代码,可以自定义修改,令输出不再固定于范例格式。
快速开始
克隆 whisper.cpp
git clone git@github.com:ggerganov/whisper.cpp.git获取模型
为了能够在C/C++中加载,OpenAI提供的原始Whisper
PyTorch模型 (opens in a new tab)被转换成自定义的ggml格式。转换是通过
convert-pt-to-ggml.py (opens in a new tab)
脚本执行的。
有三种方法可以获取模型
- 使用
download-ggml-model.sh(opens in a new tab) 下载预转换的模型
例子
$ ./download-ggml-model.sh base.en
Downloading ggml model base.en ...
models/ggml-base.en.bin 100%[=============================================>] 141.11M 5.41MB/s in 22s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav- 手动下载预转换的模型
ggml 模型可以从以下位置获取:
- https://huggingface.co/ggerganov/whisper.cpp/tree/main (opens in a new tab)
- https://ggml.ggerganov.com (opens in a new tab)
下载由OpenAI 提供的其中一个模型 (opens in a new tab),并使用 convert-pt-to-ggml.py (opens in a new tab) 脚本生成 ggml 文件。
示例转换,假设原始的 PyTorch 文件已下载到 ~/.cache/whisper。将 ~/path/to/repo/whisper/ 更改为您 Whisper 源代码副本的位置:
mkdir models/whisper-medium
python models/convert-pt-to-ggml.py ~/.cache/whisper/medium.pt ~/path/to/repo/whisper/ ./models/whisper-medium
mv ./models/whisper-medium/ggml-model.bin models/ggml-medium.bin
rmdir models/whisper-medium编译
现在,我们构建主示例。
# build the main example
make运行
注意,当前whisper.cpp的main示例仅支持16bit的wav媒体文件!所以在执行前需要先把媒体文件转为这个格式。
可以通过如下命令解决:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wav./main -m models/ggml-base.en.bin -f output.wav微调模型
社区正在努力创建使用额外训练数据进行细调的 Whisper 模型。例如,这篇博文 (opens in a new tab)描述了使用 Hugging Face (HF) Transformer 实现的 Whisper 进行微调的方法。
生成的模型与原始的 OpenAI 格式略有不同。要读取 HF 模型,您可以使用 convert-h5-to-ggml.py (opens in a new tab) 脚本,如下所示:
git clone https://github.com/openai/whisper
git clone https://github.com/ggerganov/whisper.cpp
# clone HF fine-tuned model (this is just an example)
git clone https://huggingface.co/openai/whisper-medium
# convert the model to ggml
python3 ./whisper.cpp/models/convert-h5-to-ggml.py ./whisper-medium/ ./whisper .内存占用
| Model | Disk | Mem |
|---|---|---|
| tiny | 75 MiB | ~273 MB |
| base | 142 MiB | ~388 MB |
| small | 466 MiB | ~852 MB |
| medium 1.5 GiB | ~2.1 GB | |
| large | 2.9 GiB | ~3.9 GB |
模型量化
whisper.cpp 支持对 ggml 模型进行量化,从而减少内存占用。要量化模型,请使用以下命令:
# quantize a model with Q5_0 method
make quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wavCore ML 支持
在苹果系列芯片的设备上,编码器推断可以通过 Core ML 在苹果神经引擎(ANE)上执行。这可以导致显著的加速,与仅 CPU 执行相比,速度提高了 3 倍以上。以下是生成 Core ML 模型并将其与 whisper.cpp 一起使用的说明:
安装所需要的库
pip install ane_transformers
pip install openai-whisper
pip install coremltools- 想要成功安装
coremltools,你必须要安装 XCode 并且执行xcode-select --install安装命令行工具(一般安装git时这个也会一起安装)。 - 建议使用conda创建python虚拟环境,并且使用python 3.10版本 - 建议使用macos14即以上版本。
生成 Core ML 模型
举例如果是生成基于 base.en 模型的 Core ML 模型,执行以下命令:
./models/generate-coreml-model.sh base.en打包编译
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config Release运行
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...N卡支持
在支持n卡的机器上,可以开启N卡加速。
请确保你安装了cuda (opens in a new tab)
make clean
WHISPER_CUBLAS=1 make -j实时音频转文字
make stream
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000信心程度显示
这种方式下会通过使用不同的颜色显示文字来表示 whisper.cpp 对音频的识别信心程度。
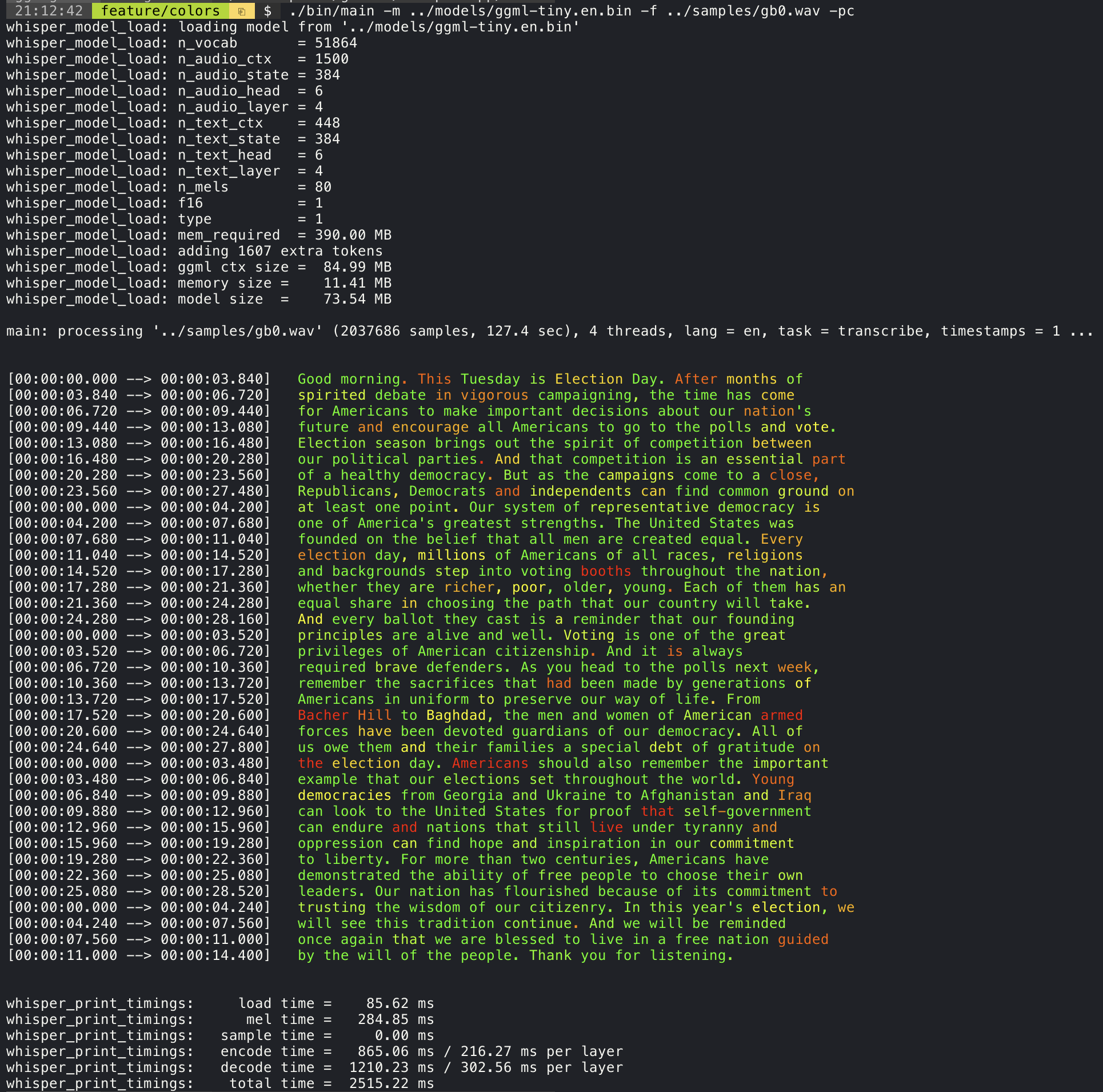
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors实时字幕式
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4